







(Перед вами перевод бесплатного курса «Product Recommendations Course» от компании Dynamic Yield. Если вы здесь впервые, то лучше начните сначала)
Автор английской версии: Влади Рожавски, директор по Data Science
Глубокое обучение (deep learning, DL) и его способность органично предсказывать, какой следующий товар/продукт заинтересует посетителя, в значительной степени определяет будущее всего персонализированного контента и товарных рекомендаций.
В этой статье мы пробежимся по ключевым понятиям глубокого обучения (deep learning) и разберемся, почему все больше компаний начинают использовать этот метод — и как они адаптируют глубокое обучение, столь удачно применяемое в обработке естественных языков (NLP), для формирования товарных рекомендаций.
Что же такое глубокое обучение (deep learning)?
Последние десять лет научный мир пребывает в восторге от того, насколько успешно работают методы глубокого обучения. Во многом благодаря этому успеху тема искусственного интеллекта (artificial intelligence, AI) в последние годы набрала значительную популярность. Самые крупные прорывы случились в области компьютерного зрения и обработки естественных языков (NLP) именно благодаря глубокому обучению (deep learning).
Глубокое обучение (deep learning) — это подвид машинного обучения (machine learning, ML) который использует алгоритмы, которые по своей структуре и функциям напоминают человеческий мозг.
То есть, говоря о глубоком обучении (deep learning), специалисты по data science, как правило подразумевают семейство алгоритмов, которые в абстрактном виде выглядят и работают как нейронные сети человека. По сути это напоминает ряд нейронных узлов, связанных друг с другом подобно паутине, каждый из которых получает входную информацию (input information), обрабатывает ее — и передает в соседние узлы.
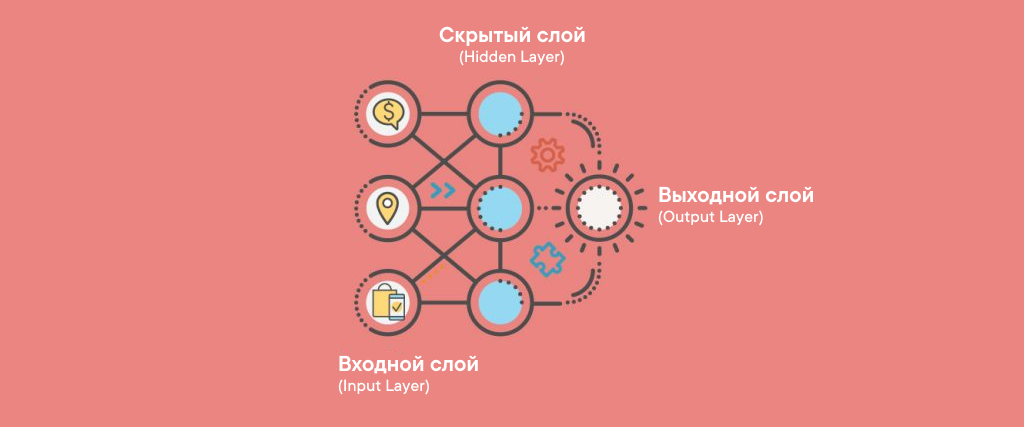
Архитектура всех моделей глубокого обучения (deep learning models) представляет собой многослойную структуру, где каждый слой состоит из узлов, выполняющих определенные математические операции — так называемые “функции активации” (activation functions).
Обычно выделяют три типа таких слоев: входной (input), скрытый (hidden) и выходной (output). См. рис. 1
Рост популярности глубокого обучения (deep learning)
Есть множество причин, почему глубокое обучение (deep learning) находит все более широкое применение. Первая причина — в отличной консолидации потребностей глубокого обучения в вычислительных мощностях (computational capacity) с растущей производительностью (power) облачных решений.
Большинство традиционных моделей машинного обучения (machine learning models) анализируют данные линейно, в то время как архитектура системы глубокого обучения позволяет обрабатывать данные нелинейно. За счет этого алгоритмы глубокого обучения (deep learning algorithms) могут более эффективно “добывать” из данных нужную информацию.
Но самое большое преимущество глубокого обучения — это его способность автоматически создавать новые признаки (features). Признаки (features) — это переменные (такие как возраст, регион, день недели и т.п.), которые используются, чтобы предсказывать определенное поведение — например, покупку. В отличие от традиционного машинного обучения (machine learning), глубокое обучение (deep learning) строит из начального набора заданных признаков (features) множество новых признаков (features) на базе разных — часто непредсказуемых (как из “черного ящика”) — комбинаций.
Так почему не все проблемы машинного обучения (ML) решаются посредством глубокого обучения (DL)?
Одна из причин в том, что алгоритмы глубокого обучения (DL algorithms) имеют фору перед алгоритмами традиционного машинного обучения (ML algorithms) только когда им достаточно данных. Поэтому предпочтение часто отдается именно алгоритмам машинного обучения (ML algorithms), которые требуют меньше данных.
Техникам deep learning также нужно больше времени на обучение, в результате чего для проведения нужных вычислений нужна более мощная инфраструктура — а это повышает затраты на сервера. Ну и наконец, интерпретируемость решений на базе глубокого обучения (DL-based decisions) ниже в сравнении с традиционными ML-алгоритмами потому что из-за трансформаций, происходящих в процессе моделирования, сложно понять, насколько входящая информация (input information) действительно повлияла на исходящий результат (output result).
А дальше появились рекомендации на базе глубокого обучения (deep learning)
Недавно глубокое обучение (deep learning) сделало первые шаги в мир рекомендательных архитектур — все благодаря идеальной параллели между обработкой естественных языков (NLP) и рекомендательными фреймворками (recommender frameworks). И та, и другая область имеет последовательную природу и ставит своей целью понять, каким будет следующий органичный элемент в последовательности.
Для примера: функция Smart Compose (“Умный ввод”) в Gmail уже доказала эффективность применения глубокого обучения (deep learning) для предсказания следующего слова в предложении. Если представить, что каждое напечатанное слово в электронном письме — это некий товар, с которым взаимодействовал посетитель, и применить ту же концепцию “предсказания, что дальше”, то получим как раз рекомендации. Это открывает огромный потенциал возможностей для онлайн-торговли. И хотя современные продавцы только начинают осваивать этот потенциал, у них в распоряжении уже есть достаточно инструментов для решения самых разных задач (challenges), связанных с рекомендациями, в пространстве больших данных (big data).
Возможности глубокого обучения (deep learning) практически безграничны — все благодаря его умению улавливать нелинейные и нетривиальные связи, например между пользователями и товарами, а также способности обрабатывать очень большие объемы информации. Таким образом, глубокое обучение может генерировать такие качественные рекомендации, каких отрасль прежде не видела.
Вот несколько примеров информации, которую может принимать в расчет глубокое обучение:
- Контекстная информация — дата, погода, давность взаимодействия (recency), тип взаимодействия (engagement-type), цена товара, страница (page)
- Текстовая информация — ключевые слова товара, отзывы, поисковые запросы пользователей
- Визуальная информация — визуальное сходство между товарами
Товарные рекомендации на базе глубокого обучения (deep learning)
Если учесть направление исследований и текущие разработки в области глубокого обучения (deep learning), можно выделить три области его применения для усиления рекомендательных движков:
- Рекомендации на базе контента (Content-based recommendations): когда для генерации рекомендаций мы полностью задействуем информацию в профиле пользователя и в описании товара
- Рекомендации на базе совместной фильтрации (Collaborative filtering-based recommendations): когда при генерации рекомендации мы отталкиваемся от прошлого поведения и предпочтений пользователя, не принимая во внимание личную информацию (например то, как пользователь оценил товар).
- Гибридные рекомендации (Hybrid method recommendations): комбинация методов рекомендаций базе контента и на базе совместной фильтрации.
Совместная фильтрация (collaborative filtering) долгое время была стандартом индустрии и считалась основным методом генерации персонализированных рекомендаций. При совместной фильтрации (collaborative filtering) используется матрица оценки пользователей-товаров (user-product matrix of ranking), которая позволяет определить вероятность, что конкретный пользователь заинтересуется конкретным товаром.
Объясним на пальцах: если пользователю по имени Дженнифер нравятся товары А и В, а другой покупательнице пришлись по душе товары А, В и С, то система сделает вывод, что нашей Дженнифер товар С тоже понравится. (Рис. 2)
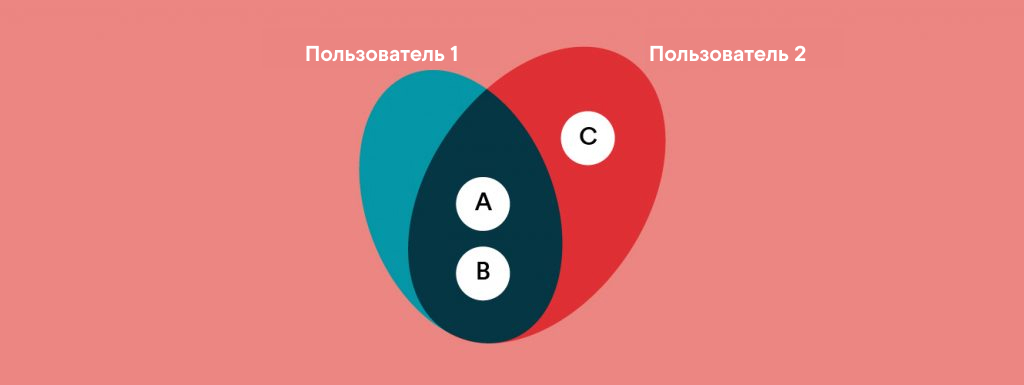
Сфера применения совместной фильтрации (collaborative filtering) очень широка. Метод позволяет делать точные и разнообразные рекомендации; при этой системе не нужно понимать суть каждого конкретного товара. И все же глубокое обучение (deep learning) “открывает” совершенно новый уровень сложности.
Алгоритмы Item2Vec
Item2Vec — это е-коммерсовый аналог техники распознавания естественных языков word2vec. Алгоритмы глубокого обучения (deep learning algorithms) фиксируют совместное появление элементов в истории просмотров пользователя и генерируют более точные рекомендации.
Поскольку метод item2vec основан на глубоком обучении (deep learning), у него есть ряд технических преимуществ:
- Масштаб (Scale) — можно обучить алгоритм на огромных объемах данных
- Актуальность (Relevancy) — алгоритм можно обучать очень часто и быстро, потому что обучение такой модели может идти в рамках одного скрытого слоя (hidden layer). Таким образом, учитываются все последние изменения на сайте.
- Охват всего каталога (Catalog coverage) — нет никаких ограничений по объему файла с данными о товарах (feed), так что система учитывает и может порекомендовать каждый товар.
- Реальное время (Real-time) — алгоритм учитывает самые свежие действия пользователя и выдает рекомендации с минимальной задержкой (very low latency).
Немного о том, как это работает.
Item2vec — это представление слова в виде числового вектора. Глубокое обучение определяет этот вектор посредством моделирования совместного появления товаров (items co-occurrence). Каждый вектор содержит в себе важную информацию о соседних товарах (items), которые часто появляются вместе с текущим. Эти соседние товары называются контекстом (context). (Рис. 3)
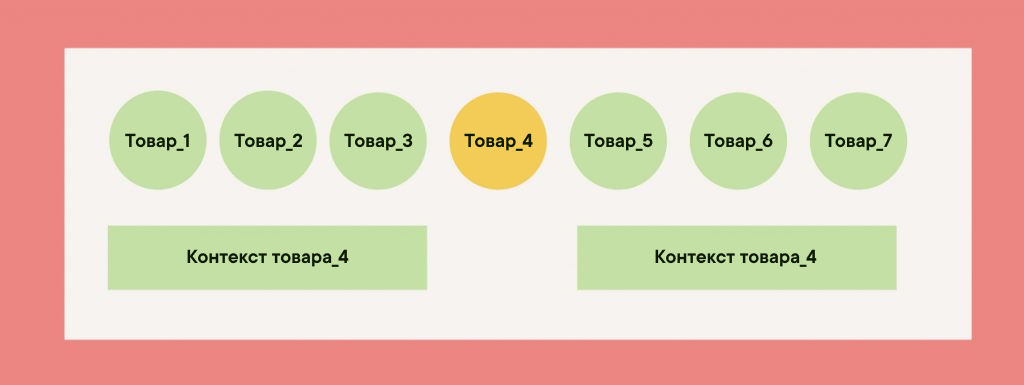
С методом item2vec товар можно “вывести” из контекста — товаров, которые как правило его окружают — а сходство контекстов подразумевает сходство потребительских паттернов (consuming patterns), связанных с этими товарами. То есть чем чаще два конкретных товара появляются в похожих (similar) контекстах. чем ближе будут представляющие их векторы.
Теперь, когда каждый товар в каталоге представлен неким числовым вектором и близость (similarity) векторов отражает близость контекстов этих товаров, можно подавать главное “блюдо”: свежие товарные рекомендации, основанные на самых актуальных интересах пользователя. Для генерации таких рекомендаций достаточно найти товары с векторами, близкими к векторам недавно просмотренных товаров. Подобную близость (similarity) между векторами называют косинусным сходством (Cosine Similarity). И поскольку товары с самым высоким косинусным сходством вероятно будут наиболее релевантными, их стоит рекомендовать пользователю.
Вывод и рекомендации: Deep learning (DL) — не просто модное словечко
Сегодня компании, ориентированные на качественный пользовательский опыт и постоянный рост дохода, должны уметь максимально точно предсказывать предпочтения пользователей и динамически рекомендовать релевантные товары.
Постепенно алгоритмы становятся все сложнее, и мы считаем, что глубокое обучение (deep learning) со временем будет самой ходовой стратегией в индустрии — и в ближайшем будущем вытеснит совместную фильтрацию (collaborative filtering) с ее ограниченными рекомендательными возможностями.
← Назад | Продолжение (Глава 7) →