







Авторы английской версии: Шана Пилевски (Shana Pilewski), директор по маркетингу, Dynamic Yield
Наша задача, как маркетологов — постоянно анализировать поведение посетителей сайта, и продукты, которые им интересны, чтобы глубже понимать, как они взаимосвязаны. С этим пониманием мы можем создавать такие опыты взаимодействия, которые действительно нравятся нашим посетителям.
Однако со временем история взаимодействий посетителя с сайтом растет (например, клиент магазина одежды отсматривает всё больше брендов, цветов, стилей, ценовых категорий и т.п.) и становится сложнее понимать, какие из множества его взаимодействий были действительно значимыми. Поэтому истинная причина вовлеченности (engagement) посетителей часто теряется в паутине сложных данных.
В результате начинается игра в угадайку: мы начинаем тестировать разные комбинации условий таргетинга (targeting conditions) в надежде, что правильный опыт взаимодействия наложится на правильную аудиторию. В качестве альтернативного решения проблемы, на маркетинговой арене появился такой метод как профили сходств (affinity profiles). Суть метода в том, что когда пользователь взаимодействует с продуктом, ему присуждается оценка (score), на основе метаданных связанных с этим продуктом. Это позволяет маркетологам точнее предсказывать, какие продукты будут актуальны для этого пользователя в будущем.
Однако несмотря на явные преимущества метода, индустрия его пока не “распробовала”. В этой статье я расскажу, что такое сходства (affinity) сегодня, и постараюсь раскрыть их огромный неосвоенный потенциал.
Как вычислить сходство (affinity)
Составление профилей сходств (affinity profiling) начинается с того, что мы фиксируем каждый эпизод вовлеченного взаимодействия пользователя (engagement) с цифровым объектом (digital property), а потом собираем все характеристики продукта, которые можно ассоциировать с этим взаимодействием.
Памятка: сигналы о сходстве пользователей (User Affinity Signals):
| Тип взаимодействия: Как пользователь взаимодействует с продуктом | Характеристики продукта: Особенности данного продукта |
| Просмотр продукта Добавление в корзину Покупка Настройка фильтра Добавление в список покупок (wishlist) Индивидуальное взаимодействие | Цвет: красный Пол: мужской Модель: футболка Категория: бег |
К примеру, давайте рассмотрим такой простой клиентский путь (customer journey):
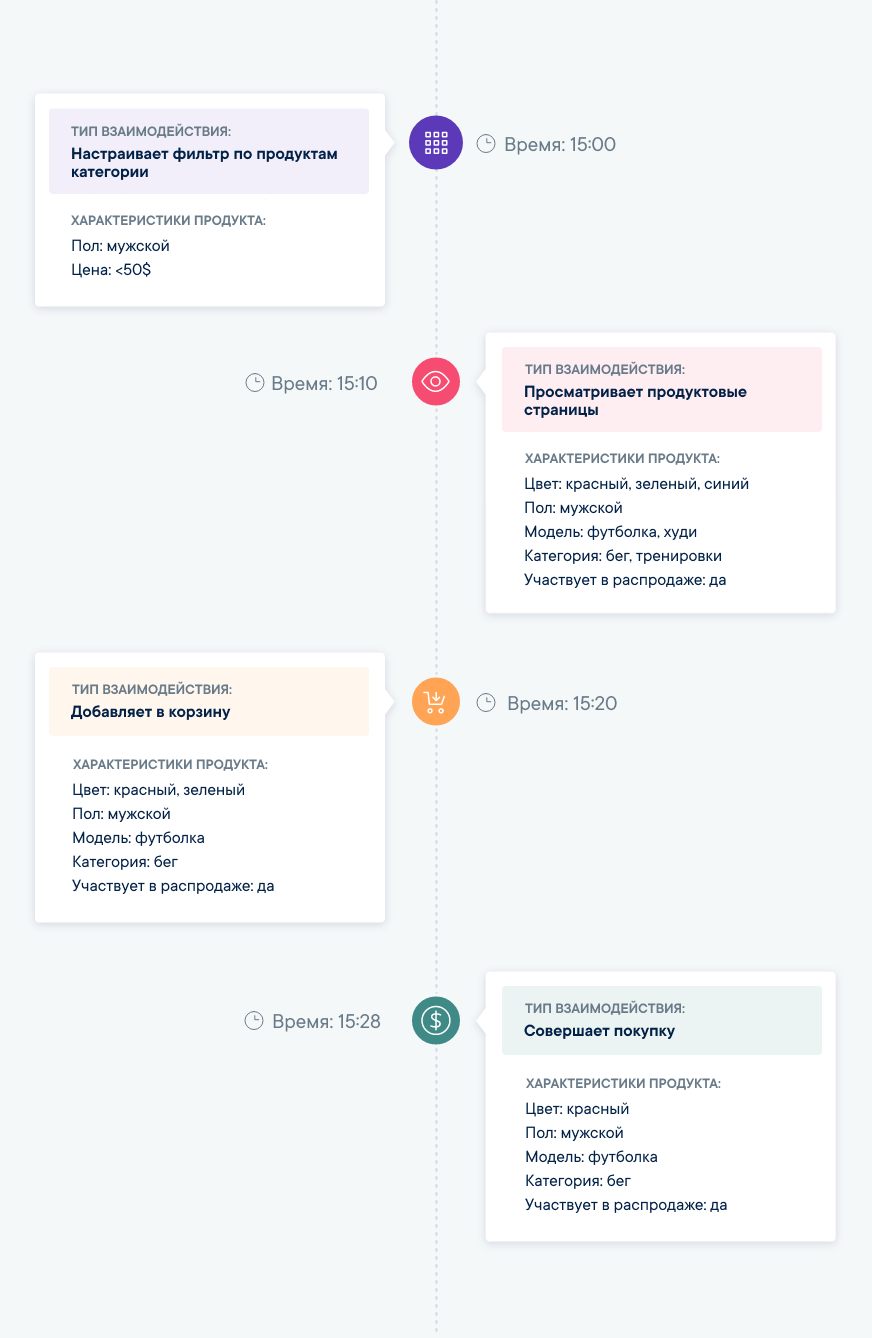
В контексте отдельно взятого посетителя, мы зафиксировали 4 просмотра страницы с товаром зеленого цвета, 6 просмотров страниц с красным товаром и 2 просмотра — с синим. Кроме того, все просмотренные товары обладали следующими характеристиками: “мужской пол”, “футболка”, “дешевле 50$”. Впоследствии посетитель добавил два товара (зеленую и красную футболку) в корзину, а купил только красную футболку.
| Характеристика | Цвет | Модель | Пол | Ценовой диапазон | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Значение: | Зеленый | Красный | Синий | Футболка | Безрукавка | Майка на бретельках | Мужчина | Женщина | Мальчик | Девочка | <$50 | >$50 |
| Просмотры (Product view) | 4 | 6 | 2 | 12 | 0 | 0 | 12 | 0 | 0 | 0 | 12 | 0 |
| Добавления в корзину (Add to cart) | 1 | 1 | 0 | 2 | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 0 |
| Покупки (Purchase) | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
Характеристика: Цвет
| Значение | Зеленый | Красный | Синий |
|---|---|---|---|
| Просмотры (Product view) | 4 | 6 | 2 |
| Добавления в корзину (Add to cart) | 1 | 1 | 0 |
| Покупки (Purchase) | 0 | 1 | 0 |
Характеристика: Модель
| Значение | Футболка | Безрукавка | Майка на бретельках |
|---|---|---|---|
| Просмотры (Product view) | 12 | 0 | 0 |
| Добавления в корзину (Add to cart) | 2 | 0 | 0 |
| Покупки (Purchase) | 1 | 0 | 0 |
Характеристика: Пол
| Значение | Мужчина | Женщина | Мальчик | Девочка |
|---|---|---|---|---|
| Просмотры (Product view) | 12 | 0 | 0 | 0 |
| Добавления в корзину (Add to cart) | 0 | 0 | 0 | 0 |
| Покупки (Purchase) | 0 | 0 | 0 | 0 |
Характеристика: Цена
| Значение | <$50 | >$50 |
|---|---|---|
| Просмотры (Product view) | 12 | 0 |
| Добавления в корзину (Add to cart) | 2 | 0 |
| Покупки (Purchase) | 1 | 0 |
Вот примерно так может выглядеть вся сессия целиком, включая значения характеристик и типы взаимодействий, которые будут учитываться при выставлении оценки (scoring).
Веса оценки сходства (affinity score)
Каждый раз, когда пользователь взаимодействует с продуктом, оценка по каждому значению характеристики обновляется в зависимости от типа взаимодействия с ней, а также от времени взаимодействия.
Вовлеченность (ENGAGEMENT)
Чтобы убедиться, что данные о взаимодействии имеют какую-то ценность, надо установить корреляцию между этим взаимодействием и значением характеристики. Сегодня мы делаем это путем присвоения веса каждому вовлеченному взаимодействию (engagement), в зависимости от предполагаемого уровня намерений пользователя. После этого количество взаимодействий (engagement) суммируется по каждой характеристике.
В зависимости от алгоритма расчета сходства (affinity algorithm), веса по умолчанию могут быть такими:
- Покупки: 4X
- Добавления в корзину: 3X
- Добавления в список покупок (wishlist): 2X
- Просмотры продукта: 1X
- Другие взаимодействия
Понятно, что чем выше уровень намерений пользователя в контексте конкретного взаимодействия, тем выше будет вес, который мы присвоим этому взаимодействию. К примеру, вес взаимодействия типа “покупка” будет выше, чем вес “добавления в корзину”, а “добавление в корзину”, в свою очередь, весомее чем “просмотр продукта”. С этого момента каждое взаимодействие мы будем умножать на его вес.
Оценка вовлеченности (Engagement score) = вес данного типа взаимодействия (interaction type weight) x количество взаимодействий с данным значением характеристики (attribute value count)
Так что если вес “покупки” равен 4, “добавления в корзину” — 2, а “просмотра продукта” — 1, суммарная оценка по значению “цвет: красный” (“color:red”) составит (1×6) + (2×1) + (4×1) = 12.
| Вес | Цвет | |||
|---|---|---|---|---|
| Зеленый | Красный | Синий | ||
| Просмотры (Product view) | 1 | 4 | 6 | 2 |
| Добавления в корзину (Add to cart) | 2 | 1 | 1 | 0 |
| Покупки (Purchase) | 4 | 0 | 1 | 0 |
| Оценка (Score) | 6 | 12 | 2 |
Теперь эти оценки (scores) можно использовать для создания профиля сходств (affinity profile), который по сути представляет собой отранжированный список предпочтительных цветов, категорий, брендов и т.п., собранный на основании активности клиента.
Актуальность (RECENCY)
Со временем поведение пользователей и их предпочтения меняются, поэтому профили сходств (affinity profiles) нужно обновлять и уточнять с каждым новым просмотром страницы, действием или событием, в режиме реального времени.
Таким образом, актуальность (recency) каждого взаимодействия тоже учитывается: алгоритм отдает предпочтение новым данным над старыми.
При оценке обычно используются три временных периода:
- В реальном времени или в рамках текущей сессии: 8X
- В недавней истории или за предыдущий месяц: 2X
- За все время или за последние 6 месяцев: 1X
Далее мы “наслаиваем” эту информацию на оценку значений характеристик: то есть мы делаем поправку не только на вес взаимодействия (interaction weight), но и на вес актуальности (recency weight).
Оценка актуальности (Recency score) = вес актуальности (recency weight) x (вес взаимодействия (interaction weight) x количество взаимодействий с данным значением характеристики (attribute value count))
Если предположить, что этот самый пользователь через две недели вернется на сайт и купит зеленую футболку, которую до этого оставил в корзине, то суммарная оценка по значению “цвет: зеленый” (“color:green”) составит 2[(1×4) + (2×1) + (4×0)] + 8(4×1) = 44.
| Характеристика | Цвет | ||||
|---|---|---|---|---|---|
| Актуальность (recency) | Значение: | Вес: | Зеленый | Красный | Синий |
| Недавняя история (Recent History) (вес = 2) | Просмотры (Product view) | 1 | 4 | 6 | 2 |
| Добавления в корзину (Add to cart) | 2 | 1 | 1 | 0 | |
| Покупки (Purchase) | 4 | 0 | 1 | 0 | |
| Оценка (Score) | 6x2=12 | 12x2=24 | 2x2=4 | ||
| Реальное время (вес = 8) | Покупки (Purchase) | 4 | 1 | 0 | 0 |
| Оценка (Score) | 4x8=32 | 0 | 0 | ||
| Итоговая оценка (Total score) | 44 | 24 | 4 |
Актуальность: Недавняя история (Recent History) (вес = 2)
| Характеристика: | Цвет: | ||
|---|---|---|---|
| Зеленый | Красный | Синий | |
| Просмотр продукта (Product View) Вес: 1 | 4 | 6 | 2 |
| Добавление в корзину (Add to Cart) Вес: 1 | 1 | 1 | 0 |
| Покупка (Purchase) Вес: 1 | 0 | 1 | 0 |
| Оценка (Score) | 6x2=12 | 12x2=24 | 2x2=4 |
Актуальность: Реальное время (Real Time) (вес = 4)
| Характеристика: | Цвет | ||
|---|---|---|---|
| Зеленый | Красный | Синий | |
| Покупка (Purchase) Вес: 4 | 0 | 1 | 0 |
| Оценка (Score) | 4x8=32 | 0 | 0 |
| Итоговая оценка (Total Score) | 44 | 24 | 4 |
Теперь наш профиль сходств (affinity profile) отражает две важных оценки (оценку вовлеченности и оценку актуальности). Таким образом мы теперь можем показывать пользователю те продукты, которые скорее всего привлекут его внимание в данный момент времени. А за счет нормализации данных сайта, можно даже выявлять характеристики «длинного хвоста», связанные с покупкой. Так что здесь можно добиться очень чистых результатов, не обусловленных только лишь популярными или наиболее “ходовыми” характеристиками.
Отпускаем сходства (affinity) в далекое плавание
Вышеописанный метод вычисления сходств прост и эффективен. С его помощью, подставляя метаданные о продукте в две простые формулы, мы можем выявлять взаимосвязи между характеристиками из разных продуктовых областей (product fields).
Это довольно понятная и прозрачная схема, которую вы легко сможете донести до стейкхолдеров (stakeholders) — лишний раз подчеркнув важность качественно прописанных характеристик в описании продукта. Новые продукты тоже вполне естественно встраиваются в эту систему: не нужно ничего специально устанавливать или настраивать.
Однако, основной потенциал сходств (affinities) еще далеко не раскрыт. Машинное обучение открывает перед нами более продвинутые возможности ранжирования и позволяет выявлять все более сложные корреляции.
С новыми “умными” сходствами (affinities) можно будет настраивать переменные в уравнении расчета оценок: то есть вы уже не будете использовать одну и ту же статичную формулу расчета для всех посетителей. К примеру, вы сможете откорректировать вес одних характеристик с поправкой на фактор долгосрочного взаимодействия, а другие характеристики, наоборот, сильнее связать с текущей сессией.
Обучаясь, модели глубокого обучения (Deep Learning models) анализируют множество прошлых сеансов взаимодействия, которые завершились конверсией. Это означает, что нейросети могут сами присваивать веса разным взаимодействиям, определять временные рамки для каждой характеристики и выявлять корреляции между характеристиками.
Далее они могут в рамках активной сессии с пользователем ранжировать значения характеристик (допустим, цвета) по вероятности добавления в корзину / покупки — даже если речь идет о цветах или брендах, с которыми пользователь не знаком. А по мере дальнейшей нормализации данных, в расчет станут приниматься и такие важные контекстуальные нюансы, как тип сайта, ассортимент, дата и время.
Можно сказать, что моделирование сходств (affinity modeling) становится все более и более персонализированным. При таком изобилии возможностей, крайне важно, чтобы команды понимали, как сходства формируются, как они анализируются, и как работают.
Для большинства современных маркетологов, данные о сходствах (affinity data) представляют собой этакий “черный ящик”: команды используют сходства для оптимизации кампаний по персонализации, но очень слабо понимают, как именно алгоритм вычисляет оценку сходств (affinity score). А проблема в том, что подход “вот вам оценка сходств, берите или уходите” больше не работает. Важно, чтобы все данные, имеющие отношение к сходствам (affinities) и характеристикам (attributes), были открытыми и легкодоступными и чтобы их можно было адаптировать (настроить / персонализировать) под конкретные запросы бизнеса.
В чем вся прелесть сходств (affinity)
Сходства (affinities) дают нам возможность точно предсказывать, чего хочет конкретный пользователь в конкретный момент времени. Чтобы ваша команда могла в полной мере использовать потенциал сходств пользователей (user affinities), у нее должен быть максимально полный доступ и контроль над данными, а также четкое понимание того, как рассчитывается оценка сходств (affinity score).
При выборе решения для персонализации (technology provider), убедитесь, что у вас будет возможность не только играть с разными переменными сходств (affinity’s variables) и использовать их в работе, но и глубоко погружаться в результаты, полученные в рамках каждой кампании.