







(Перед вами перевод бесплатного курса по A/B тестированию от компании Dynamic Yield. Если вы здесь впервые, то лучше начните сначала)
Автор английской версии: Шана Пилевски, директор по маркетингу, Dynamic Yield
На большинстве платформ для проведения экспериментов есть встроенная функция аналитики, чтобы отслеживать нужные метрики и KPI. Но прежде чем смотреть в отчеты и начинать что-то анализировать, важно понять суть двух ключевых метрик:
- Рост (аплифт, uplift): разница (в процентах) между показателями вариации и базовой (контрольной) версии. К примеру, если для вариации доход на пользователя составил 5$, а для контрольной версии — 4$, значит рост составил 25%.
- Вероятность того, что одна версия лучше другой (P2BB, Probability to Be Best): показывает, каковы шансы, что конкретная вариация будет более эффективной в долгосрочной перспективе. Эта метрика самая полезная во всем отчете с практической точки зрения — ее используют для определения победителя A/B теста. Если рост (аплифт) может варьироваться в зависимости от размера выборки, то показатель P2BB (вероятность, что одна версия лучше) учитывает размер выборки (основываясь на байесовском подходе). P2BB не начинает вычисляться, пока выборка не достигнет 1000 или не наберется 30 конверсий. Проще говоря, показатель P2BB отвечает на вопрос “Какая версия лучше?”, а рост показывает “Насколько?”
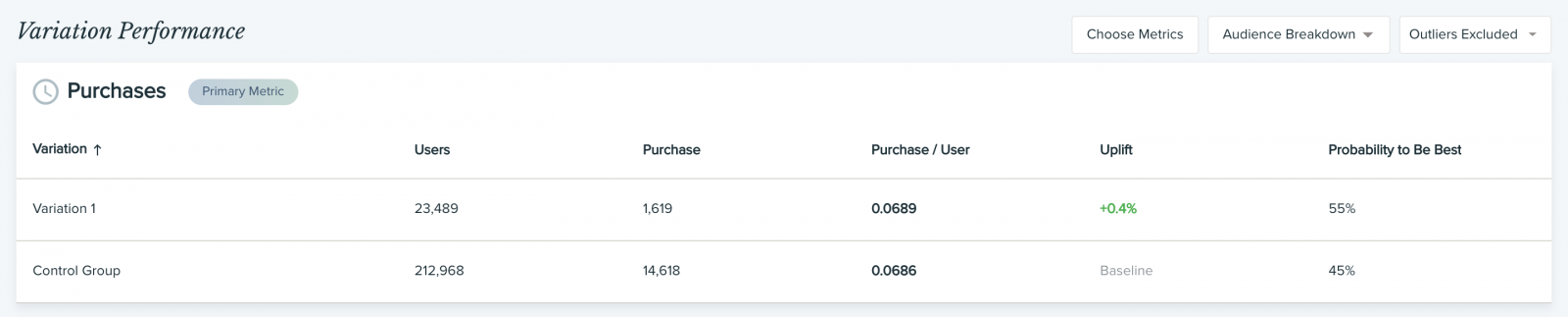
Базовый анализ
Начните с проверки результатов A/B теста: возможно, уже выделился конкретный победитель или хотя бы есть информация, какая вариация побеждает на данный момент. Если ваша платформа для тестирования не рассчитывает метрику P2BB (вероятность, что одна версия лучше другой), можете воспользоваться нашим байесовским калькулятором для A/B тестирования, чтобы обработать данные и выявить статистически значимые результаты.
Обычно, победитель объявляется, когда соблюдены следующие условия:
- Для одной из вариаций показатель P2BB превысил 95% (некоторые платформы позволяют менять порог этого показателя через настройку уровня значимости победителя).
- Прошло минимальное время тестирования (по умолчанию это 2 недели). Это делается, чтобы застраховать результаты от влияния сезонных колебаний.
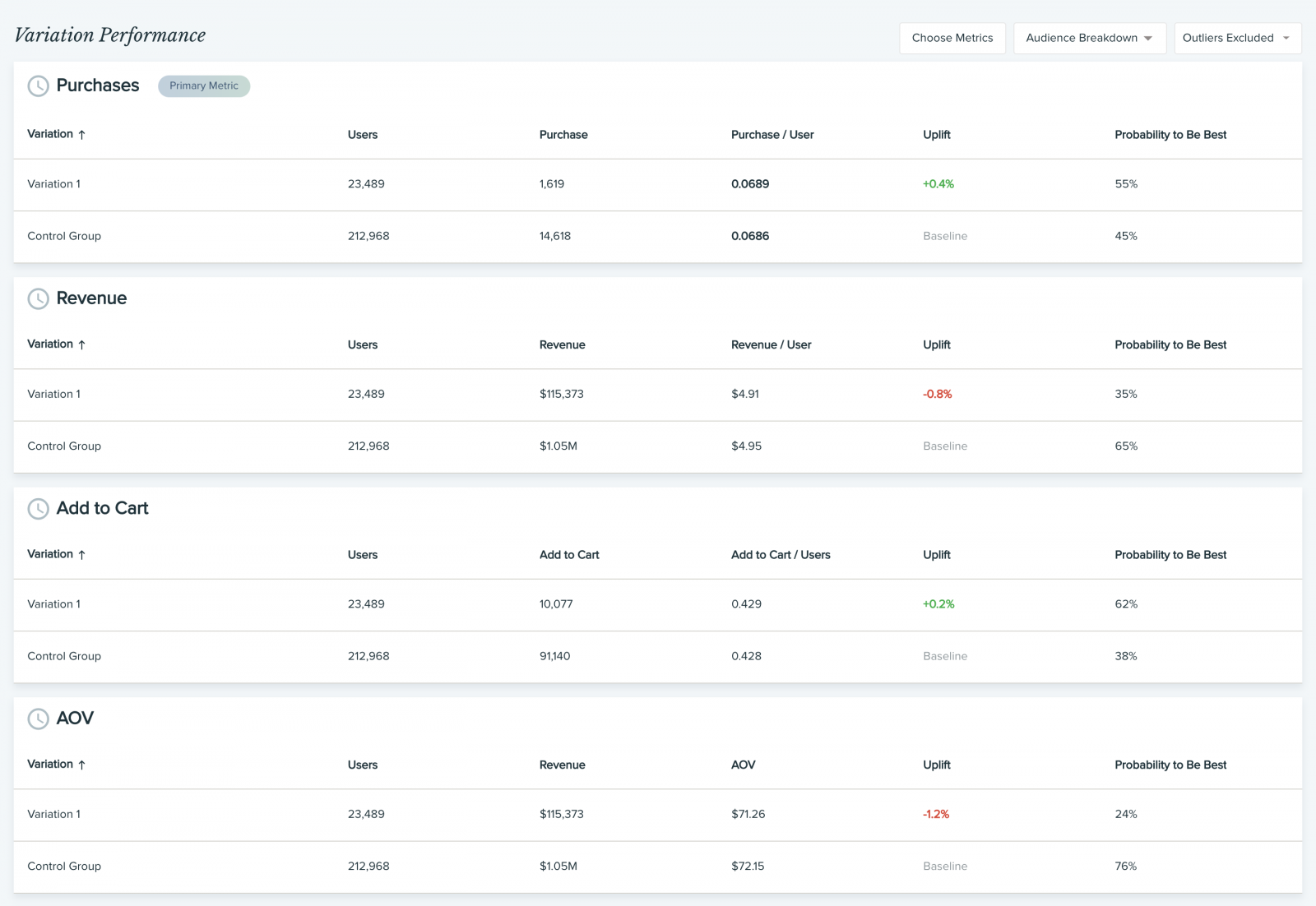
Анализ вторичных метрик
Обычно победитель тестирования определяется на основании одной ключевой метрики. Однако некоторые платформы (и Dynamic Yield в их числе) также отслеживают и дополнительные, так называемые вторичные метрики. Прежде чем вы завершите эксперимент и начнете масштабировать вариацию-победителя на всю аудиторию, рекомендуем всегда анализировать вторичные метрики, и вот почему:
- Перестраховаться от ошибки (например, победившая вариация обеспечила рост вашей ключевой метрики CTR, но повлекла падение количества покупок, объема дохода или средней стоимости заказа (AOV)).
- Раскопать ценную информацию (например, доля покупок на пользователя сократилась, но средняя стоимость заказа выроста, из чего следует, что пользователи делают покупки реже, но приобретают более дорогие товары — следовательно, генерируют больше прибыли).
По каждой вторичной метрике мы рекомендуем отслеживать рост (аплифт) и P2BB, чтобы отслеживать эффективность вариаций в сравнении.
После такого анализа будет понятно, стоит ли выкатывать одну победившую вариацию на весь трафик или лучше скорректировать распределение на основании новых данных.
Анализ состава аудитории
Еще одно направление, в которое стоит углубиться — это разбивка результатов по сегментам аудитории. Это поможет ответить на следующие вопросы:
- Как вел себя трафик из разных источников в процессе эксперимента?
- Какая вариация победила среди мобильных пользователей/ пользователей десктопов?
- Какая вариация лучше сработала для новых пользователей?
Рекомендую выделить пользователей, наиболее значимых для бизнеса, в отдельный сегмент, а также сгруппировать тех пользователей, чье поведение отличается от общей аудитории.
Опять же, по каждой аудитории нужно отслеживать рост (аплифт) и P2BB, чтобы оценить эффективность каждой вариации. Это тоже поможет определиться, стоит ли выкатывать изменения сразу на всю аудиторию.
Но иногда проигрыш в A/B тесте — это на самом деле победа!
Нет никаких сомнений, что оптимизация конверсии (CRO) и A/B тестирование работают. Они всегда помогали маркетологам, которые находятся в контакте с аудиторией и в целом знают, чего хотят посетители, выбирать максимально эффективные варианты подачи контента и существенно поднимать конверсию и доход. Однако сегодня в игру вступает персонализация. По мере того, как пользовательский опыт становится все более персонализированным, результаты экспериментов, которые не учитывают индивидуальные особенности пользователей, уже нельзя назвать однозначными; кроме того, становится все сложнее добиваться статистической значимости.
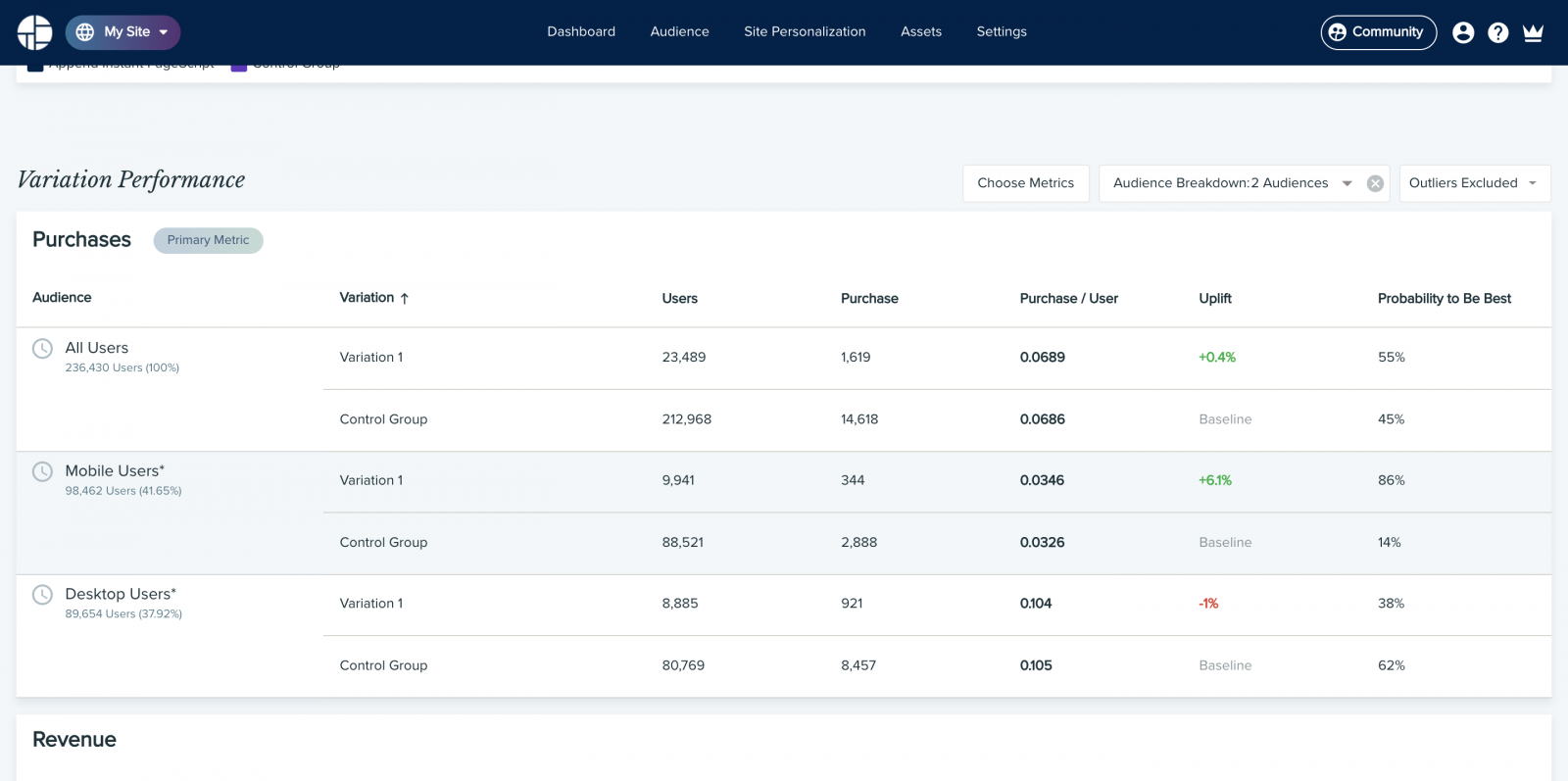
В этом сложном новом мире персонализации, где “среднестатистические пользователи” уже не могут говорить за “всех пользователей”. Это означает, что старый подход, когда мы искали некий “лучший” опыт и пытались масштабировать его на всю аудиторию, больше не работает, хотя мы и пытаемся выжать из него максимум: вычисляем нужный размер выборки, совершенствуем гипотезы и оптимизируем KPI.Сегодня мы уже не можем просто положиться на успешный эксперимент и использовать вариацию-победителя для всех. Нужно понимать, что в этом случае мы все равно игнорируем интересы определенного процента пользователей, для которых наша “лучшая” вариация таковой не является — а такой процент всегда будет. Если принять как данность эту особенность A/B тестов, становится очевидно, что даже проигрыш в A/B тесте может обернуться победой. Неудачный тест иногда помогает выявить скрытые возможности, которые при должном (персонализированном) подходе могут принести блестящие результаты. Ниже приведены результаты настоящего эксперимента, который длился порядка 30 дней. На первый взгляд тут почти ничья, и контрольная версия даже кажется эффективнее экспериментальной.
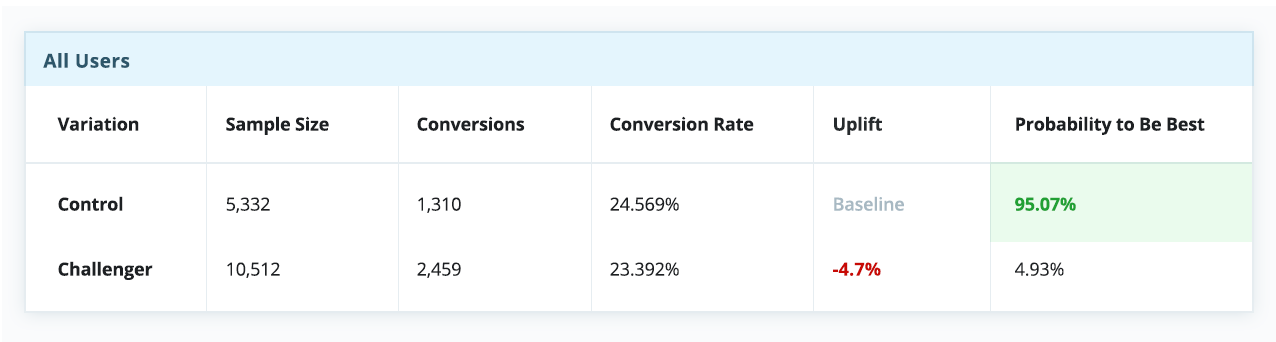
Однако если разбить эксперимент на сегменты по типам устройства — а это довольно простой и распространенный тип сегментации — история в корне меняется. Очевидно, что контрольная версия побеждает для десктопов, но сильно проигрывает среди пользователей телефонов и планшетов.
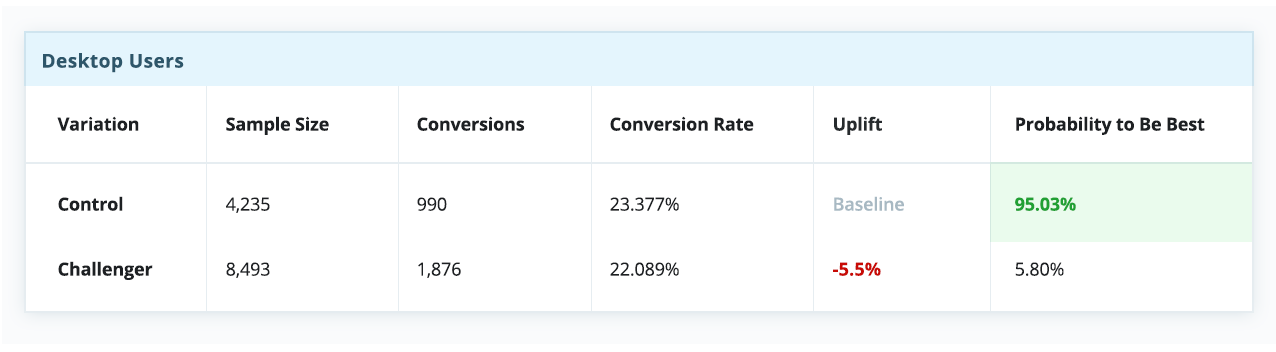
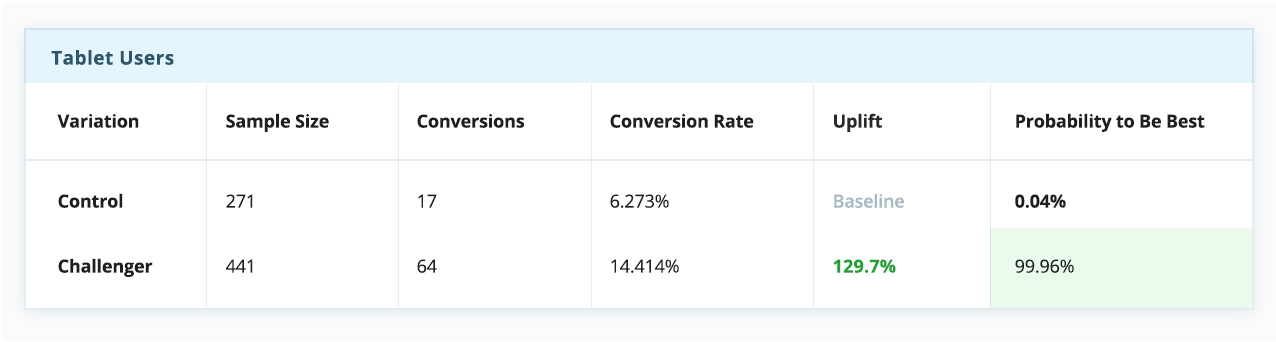
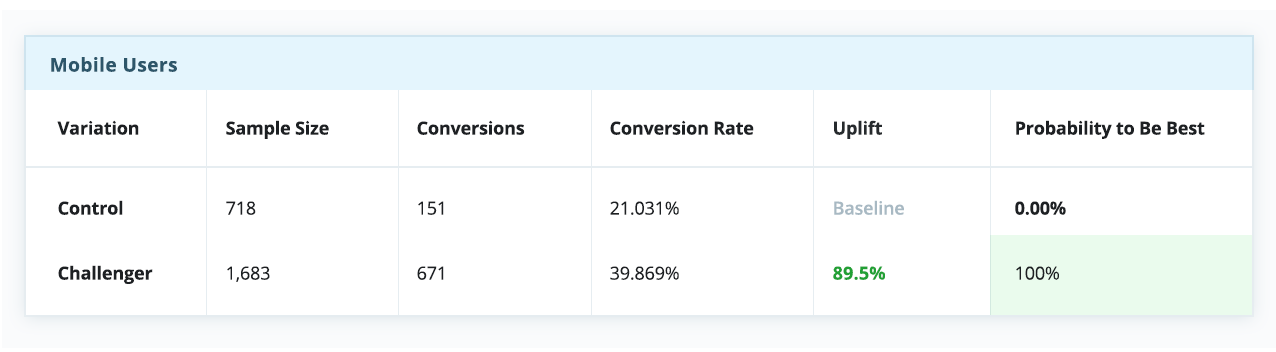
В контексте этого примера, если бы мы выбрали стратегию “winner takes all” (а многие так и делают), всей аудитории пришлось бы довольствоваться единым пользовательским опытом, якобы оптимизированным под среднестатистического пользователя — несмотря на то, что пользователи мобильных устройств явно предпочли экспериментальную вариацию.
А вот еще один пример, в котором контрольная вариация, казалось бы, проигрывает по результатам эксперимента в масштабе всей аудитории. Однако дальнейший анализ показал, что эффективнее будет показывать победившую вариацию (v2) наиболее многочисленному сегменту “прямого трафика”, а остальным пользователям продолжать показывать контрольную вариацию.
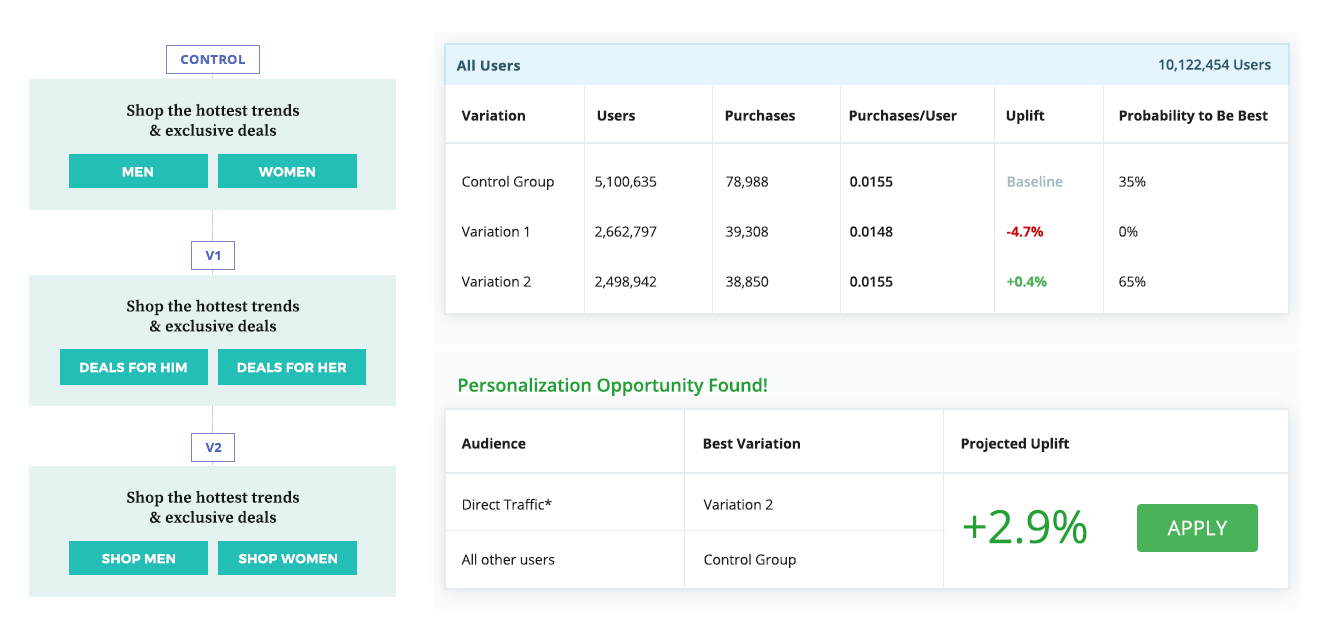
Эти примеры подчеркивают важность исследования и тщательного анализа результатов тестирования в разрезе разных сегментов аудитории. Только так вы сможете выявить скрытые возможности для оптимизации даже в тех экспериментах, где тестирование с ориентацией на среднестатистического пользователя (такого, кстати, не существует) не принесло ожидаемых результатов.
В большинстве ситуаций бывает достаточно быстрого анализа, но когда циклы тестирования идут один за другим, а приоритеты постоянно меняются бывает трудно выкроить время даже на это. Однако с ростом количества тестов, вариаций и сегментов проблема лишь усугубляется, и в результате анализ становится очень объемной задачей. Ну что, с этими знаниями, все еще хочется и дальше сохранять статус кво, читать результаты поверхностно и не делать ни шагу в сторону?
← Назад | Продолжение (Глава 15) →