







(Перед вами перевод бесплатного курса по A/B тестированию от компании Dynamic Yield. Если вы здесь впервые, то лучше начните сначала)
Автор английской версии: Идан Михаэли, директор по Data Science в Hippo Insurance
Над переводом работали Оля Жолудова и Ринат Шайхутдинов. При поддержке koptelnya.ru.
Коптельня — команда по быстрой разработке веб-приложений и сайтов.
Далеко позади те дни, когда маркетологи вносили изменения в страницы сайтов, руководствуясь чутьем и внутренним голосом. Мы живем в эру A/B тестирования — так что каждое наше решение всегда обосновано эмпирическими данными. В нашем распоряжении есть инструменты A/B тестирования, которые помогают нам использовать собранные с сайта данные для принятия более взвешенных решений. Или, говоря еще точнее, мы осознанно обобщаем данные, чтобы делать на их основании адекватные предположения о будущем. В этой статье я хочу поговорить про эволюцию инструментов, которые мы сегодня используем: начиная с базового “частотного” метода тестирования, которым активно пользовались наши предшественники (впрочем, частотные методы до сих пор активно применяются в A/B тестах) — и заканчивая новым, байесовским методом тестирования, в сторону которого уверенно движется индустрия.
В основе этих двух подходов лежит принципиально разное представление о том, что такое вероятность. Я попробую, не особо погружаясь в тяжелую математику, подсветить эту разницу и объяснить, во что она выливается на практике.
Что такое тестирование гипотез и какой классический порядок действий статистической проверки гипотез?
На заре эпохи A/B тестирования, статистика могла предложить исследователям крайне базовый набор методов для формирования статистических выводов в сценариях A/B тестирования. Вот что из себя представляет процедура, известная как “проверка гипотез”:
- Базовая вариация. Все начинается с существующей версии веб-страницы или отдельной ее части. В современных терминах она называется базовой версией, или вариацией А.
- Альтернативная вариация. Далее мы устанавливаем альтернативную вариацию (или вариацию B)
- Объем выборки. Заранее рассчитываем необходимый объем выборки — можно воспользоваться онлайн-калькулятором вроде этого. Наши расчеты будут базироваться на текущем показателе конверсии (для базовой версии он должен быть известен), минимальной разнице в показателях, которую мы хотим выявить, и необходимой статистической мощности (которая, грубо говоря, показывает насколько надежный результат нам требуется; но помните, что для более надежных результатов потребуется больший размер выборки).
- Запускаем тест и ожидаем необходимый объем выборки (не подглядываем). Запускаем тест и крутим его (чур не подглядывать раньше времени!), пока не достигнем нужного объема выборки для каждого из тестируемых вариантов. Серьезно, подглядывать нельзя (и вот почему)! Да, знаю. Люди часто не рассчитывают нужный объем выборки заранее и не могут устоять перед соблазном проверить данные поскорее. Но если вы станете подсматривать за ходом эксперимента, то при виде первых значительных результатов автоматически начнете делать неверные выводы, что может здорово повлиять на надежность результатов эксперимента. Так что подглядывать нельзя!
- Оценка результативности по p-value. Теперь, когда у нас есть выборки нужного объема, мы можем оценить результативность каждой вариации и высчитать, является ли победа более результативной вариации статистически значимой. Опять же, при помощи онлайн-калькулятора можно узнать p-value, также известной как “уровень достоверности”. Но что на самом деле такое p-value?
Неверное толкование величины p-value
Люди часто думают, что p-value — это вероятность того, что вариация B лучше, чем вариация A. Это распространенная ошибка; на самом деле p-value относится к той первоначальной гипотезе, с которой начинался наш процесс проверки гипотез.
P-value характеризует не тот “оптимистичный” случай, когда альтернатива (B) действительно лучше базовой версии. Скорее p-value относится к первоначальной, “пессимистичной” гипотезе — так называемой “нулевой гипотезе” — которая гласит, что новая вариация ничем не лучше существующей, а любые изменения — это не более, чем случайный шум. А уже далее мы стараемся опровергнуть эту гипотезу. По сути, нам надо высчитать, насколько слабые эмпирические результаты мы будем фиксировать что при условии, что нулевая гипотеза правдива. Вероятность получения этих эмпирических результатов — это как раз и есть p-value.
Если p-value ниже определенного порога (который часто принимают за 0,05), мы можем утверждать, что данные позволяют опровергнуть нулевую гипотезу и, таким образом, объявить вариацию B победителем. Вдобавок, этот фреймворк проверки гипотез позволяет нам рассчитать доверительный интервал, который показывает, насколько мы можем быть уверены, что результаты эксперимента будут актуальны в долгосрочной перспективе.
Обратите внимание, насколько это сложная и запутанный фреймворк.
Нам необходимо знать показатели базовой вариации и дождаться нужного объема выборки, прежде чем мы сможем взглянуть на данные и сделать выводы. И эти выводы будут основываться на метриках, которые на самом деле могут означать совсем не то, что думают большинство людей.
Отсюда вопрос: можно же что-то сделать, чтобы процесс был проще, интуитивнее, надежнее — и подразумевал бы меньше ограничений? Ответ: да.
Частотный подход против байесовского
В сфере статистического анализа есть две совершенно разные школы, причем у каждой есть свои многочисленные последователи. Первая школа — сторонники частотного подхода. Именно в рамках этой школы был разработан фреймворк проверки гипотез, описанный выше. Вторую — байесовскую — школу я намерен вам сейчас представить.
Разница между этими школами-конкурентами по сути сводится к разной интерпретации понятия “вероятность”. Введение в байесовскую статистику, которое я даю в этой статье, это по сути адаптация этой серии статей.
Давайте сразу рассмотрим на конкретном примере.
Ситуация: Допустим, нам нужно узнать средний рост современного американца.
Частотный подход: Для сторонника частотного подхода, эта величина неизвестна, но постоянна. Это такой естественный интуитивный подход: если бы мы измерили всех американцев одного за другим и высчитали бы среднее по полученным данным — у нас на руках действительно была бы конкретная цифра. Но поскольку мы не можем измерить каждого американца, можно взять, например, тысячу жителей, выяснить из средний рост — а потом рассчитать вероятность ошибки. Особенность частотного подхода в том, что средний рост все равно принимался бы за некую неизвестную, но постоянную величину.
Байесовский подход: Сторонники байесовской статистики смотрят на ситуацию под другим углом. Средний рост американца в байесовской статистике будет характеризоваться не числом, а неизвестным распределением (это может быть, скажем, нормальное распределение, которое по форме напоминает колокол).
Байесовская статистика и вероятность: как они взаимосвязаны
На начальном этапе наш “байесовский” исследователь располагает определенными накопленными знаниями, на основании которых может предположить, что средний рост американца находится в интервале от 50 до 250 сантиметров.
Далее он начинает измерять рост конкретных людей и с каждым новым измерением распределение становится все больше похоже на колокол, где высшей точкой будет средний показатель роста, рассчитанный на данный момент времени. И чем больше данных мы соберем — тем острее будет становиться наш “колокол”: все больше данных будет концентрироваться вокруг постоянно уточняющегося показателя среднего роста.
Для “байесовцев” вероятности сильно связаны со знаниями, которыми они располагают о событии. Это означает, к примеру, что с точки зрения байесовского подхода мы можем с уверенностью говорить о вероятности, что реальная конверсия находится в некоем заданном диапазоне — и эта вероятность будет отражением наших знаний о значении показателя конверсии на основании информации и данных, которыми мы располагаем.
В байесовском подходе концепция вероятности шире и описывает разные степени уверенности в том, насколько определенный показатель соответствует реальности. Однако, с точки зрения строгого частотного подхода, такая сущность, как вероятность наблюдения определенного показателя конверсии — это полная бессмыслица. Для “частотников” реальный показатель конверсии — это по определению одно конкретное число, а рассуждения о распределении вероятностей для конкретного числа — это математический нонсенс.
Та же логика применима при попытке измерения конверсии в онлайн-воронке. Конечно, вероятность можно оценить, руководствуясь частотным подходом: соотнести количество конверсий с общим огромных количеством триалов. Но по сути байесовцу это и не нужно: он может остановить тест в любой момент и вычислить вероятности на основании данных.
Чтобы проиллюстрировать, как распределение сходится по мере добавления новых данных, рассмотрим гипотетический пример. Заметьте, как с увеличением количества просмотров “колокол” на рисунке становится все острее:
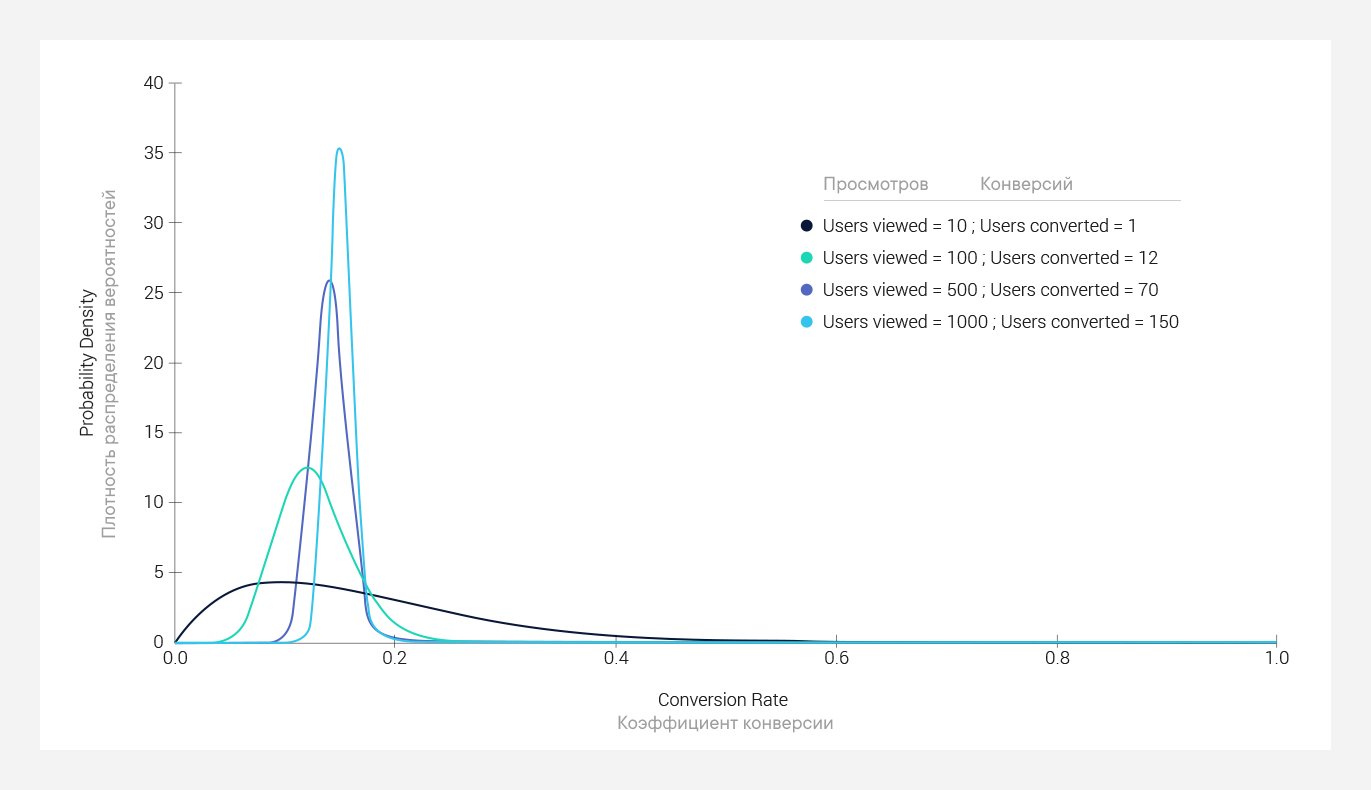
Удивительно, что это, казалось бы, небольшое различие в философии двух школ на практике порождает совершенно разные подходы к статистическому анализу данных.
Байесовский фреймворк для A/B тестирования
В основе байесовского фреймворка лежит довольно сложная математика, которой я не хочу касаться в рамках данной статьи. Скажем так: в простом калькуляторе или Excel-табличке такие вычисления не проделать. Это, как мне кажется, и является главной причиной того, что этот метод так медленно внедряется в индустрии. См. Простой гид по байесовскому А/B-тестированию на Python →
Фреймворк построен вокруг таких страшных слов, как априорная вероятность, апостериорная вероятность, теорема Байеса, бета- и гамма- распределения, метод Монте-Карло и другие.
Однако если взглянуть на вычисления, лежащие в основе байесовской статистики, как на “математический черный ящик”, становится понятно, что и входящие, и — что самое главное — исходящие данные на самом деле довольно просты и понятны. Вот так можно изобразить диаграмма работы фреймворка:
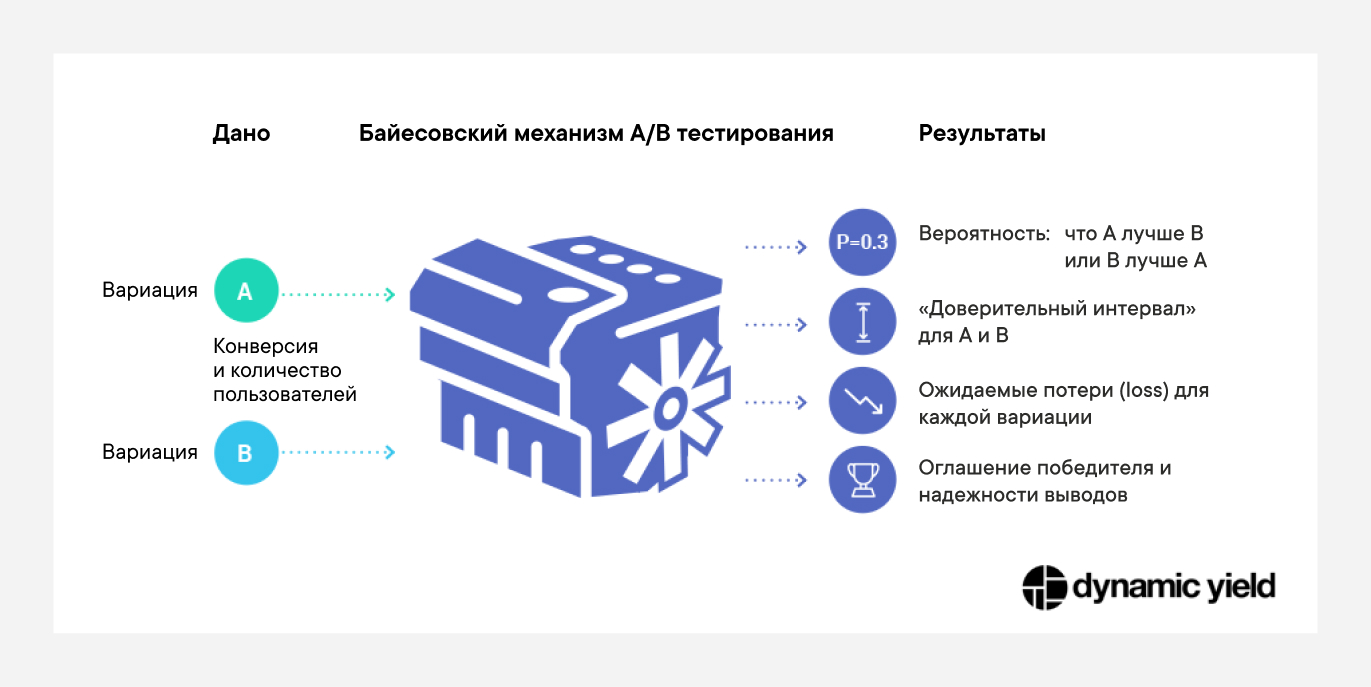
Даже не вдаваясь в конкретику, очевидно, что байесовский механизм дает ответы на более прямые вопросы, такие как:
- Какова вероятность, что А лучше B? (сравните с хитромудрым p-value, о котором мы говорили выше)
- Если мы объявим B победителем, а на самом деле эта вариация проигрышная, насколько мы просядем по конверсии?
Кроме того, этот механизм умеет считать новый вид “доверительного интервала”, который в математических терминах называется “областью наибольшей апостериорной плотности” (Highest Posterior Density Region (HPDR)). Это закрывает довольно очевидный запрос, а именно: обозначьте мне интервал конверсии, в который с 95% вероятностью попадает реальный коэффициент конверсии.
Сторонники частотного подхода в статистике тоже часто используют термин “доверительный интервал”, вот только для них он означает примерно следующее: “если бы мы повторили тест много раз и для каждого случая высчитывали собственный доверительный интервал, то в 95% случаев реальная конверсия попадала бы в этот интервал”. Как вам такое объяснение? Интуитивненько? 🙂
Давайте рассмотрим оба фреймворка в сравнении:
| Тестирование гипотез (Hypothesis Testing) | Байесовское A/B тестирование (Bayesian A/B Testing) | |
|---|---|---|
| Знания о показателях на старте | Нужны | Не нужны |
| Интуитивность | Невысокая; p-value — довольно мудреная штука | Более высокая, потому что мы напрямую вычисляем вероятность того, что A лучше B |
| Объем выборки | Определен заранее | Не нужно вычислять заранее |
| Подсматривание в процессе тестирования | Нельзя | Можно (если осторожно) |
| Скорость принятия решений | Ниже, потому что здесь больше ограничивающих допущений о распределениях | Выше, потому что здесь меньше ограничивающих допущений |
| Как выражается неуверенность | Доверительный интервал (опять же, довольно сложная интерпретация показателя; часто трактуется неверно) | Область наибольшей апостериорной плотности (HPDR) — очень интуитивная интерпретация |
| Объявление победителя | Когда достигнут необходимый объем выборки и p-value меньше заданного порога | Либо когда вероятность, что одна вариация лучше другой (P2BB) превысит заданный порог, либо когда предполагаемые потери ниже заданного порога (в этом случае между несколькими вариациями может быть объявлена ничья) |
При этом хочу отметить, что возможно провести частотное A/B тестирование такого же качества, какое обеспечивает байесовский фреймворк, но придется приложить больше усилий, чем мы привыкли прикладывать при проведении экспериментов.
Вывод и рекомедация
Подытожим: индустрия движется в направлении байесовского фреймворка A/B тестирования, потому что он проще, надежнее, интуитивнее и накладывает меньше ограничений.
P.S. Мы в Dynamic Yield перешли используем байесовский механизм не только для бинарных целей, вроде коэффициента конверсии и CTR, но и для небинарных — таких как выручка на одного пользователя (Revenue Per User).
← Назад | Продолжение (Глава 8) →